
在工程中,我们时常可以听到“大端存储”“小端存储”这类字眼,所以这个“大”和“小”到底指的是什么呢?
首先我们先来讨论一下字在机器中的存储,首先我们约定一个字是32位,半字是16位,字节是8位(对应int short char)。如果一台机器是字节可寻址的,那么能够单独寻址的最低精度就是字节。如果是字可寻址的,那么能够单独寻址的最低精度就是字。
因此,一个字在内存中看起来是这样的:
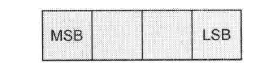
每个字里面有4个字节。(MSB指最高有效字节(most signifcant byte);LSB指最低有效字节(least signifcant byte))。例如,我们在程序中有一个整数变量为 0x11223344,那么它在内存中看起来是这样的:

然而,字节可寻址的机器中存在着一个有趣的问题,就是一个字中各个字节排列的顺序。在字节可寻址的机器中,一个4字节的字,如果从地址100开始,那么这个字其实占据了内存中100、101、102、103这4个连续字节

这4个字节组合起来就成了地址100处的一个字

假设100处的这个字的值为0x11223344,那么这4个字节在字中有两种可能的组织方式:
组织方式1:
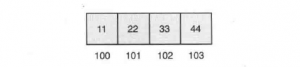
在这种组织方式中,该字的MSB(包含11)位于字的地址即100上。这种组织方式称为大端模式。
组织方式2:
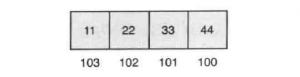
在这种组织方式中,该字的LSB(包含44)位于字的地址即100上,这种组织方式称为小端模式。
由此可见,大端还是小端是根据哪个字节处于字的地址上来区分的,如果是MSB,那就是大端;如果是LSB,那就是小端


